A modern and flexible architecture
Diagrams of the system architecture
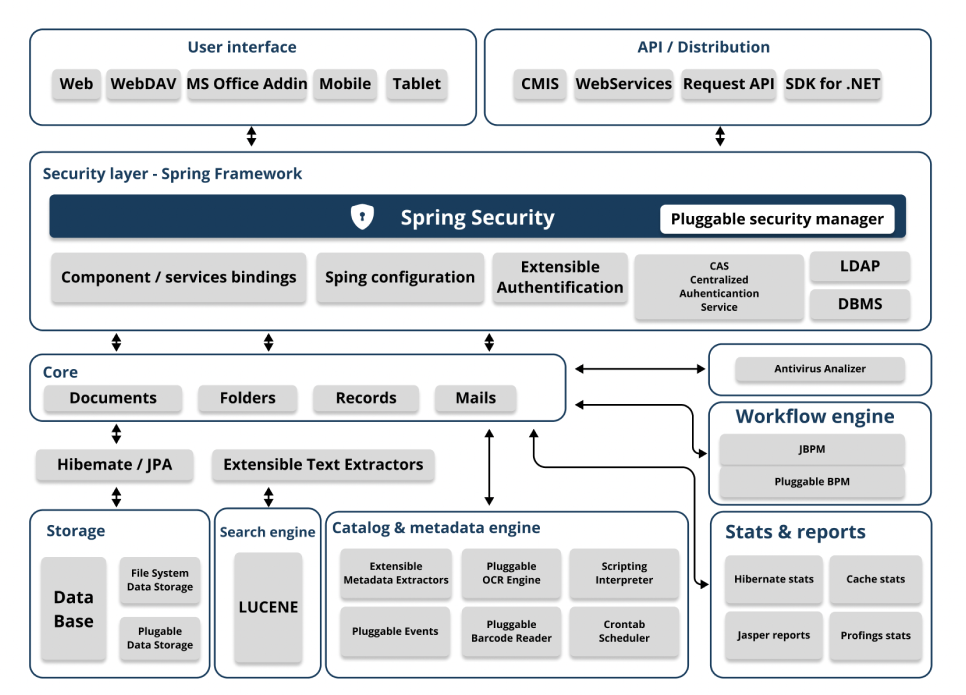
User's interface
Enables access to the application via a web browser, as well as a specific interface for mobile devices, Add-ins for Microsoft Office, or the FTP protocol among others.
API
Comprehensive API via RESTful Web services featuring nearly 500 different request types and can be used as an integration point with third-party applications.
For application development, SDKs (Software Development Kits) for Java and .NET are available, allowing easy access to the OpenKM API.
Security layer
OpenKM is a Java EE application utilizing the Spring Framework. The most relevant module is the security layer - Spring Security - which centralizes access management for users based on their credentials. Security control lies within an AccessManager module, implementing security evaluation logic in the application. The Java EE architecture implemented in OpenKM allows for customized security logic.
Authentication can be performed with LDAP, via OpenKM's own database, or through specific modules (e.g., OAUTH).
Core
The OpenKM Core centralizes and implements the management and processing logic for different types of objects that are stored in the repository. These objects are nodes of type document, folder, emails and records as well as the combination of metadata structures.
Workflow engine
OpenKM defaults to the JBPM Workflow Engine. OpenKM can integrate with any workflow engine.
Storage
OpenKM uses Hibernate for Object-Relational Mapping (ORM), supporting various relational databases (DBMS) such as PostgreSQL, MySQL, Oracle, or MS SQL Server. The metadata layer set is stored in a database (DBMS), while binary objects (documents) are stored in the file system defined by the datastore.
Search engine
The search engine enables rapid information retrieval. OpenKM uses Lucene or Elastic Search as its search engine. All objects, whether binary or not, that OpenKM works with are indexed by the search engine.
Catalog and metadata
Facilitates intelligent document cataloging by integrating with various open-source OCR engines (such as Tesseract) and commercial ones (such as Chronoscan, Abby, or Kofax among others).
Smart Tasks, task scheduler (Crontab), and reports (Jasper Reports) allow for planning, executing, and controlling the automatic metadata capture process, as well as automating complex processes in a user-friendly manner.
Antivirus
OpenKM can be integrated with most antiviruses. All binary objects are processed by the antivirus engine, ensuring the integrity of the repository and the safety of users in daily use documentation.
Statistics and reports
OpenKM's statistics and reports system empowers administrators with a robust source of information to monitor the application's status. OpenKM enables analysis of values related to Hibernate usage, second-level cache, as well as metrics related to API and core methods.